Scikit-learn#
Scikit-learn (http://scikit-learn.org/stable/) is a library built from Numpy that implements most (classical) machine learning algorithms (not deep learning).
Detailed information about this library can be found in the user’s guide: http://scikit-learn.org/stable/user_guide.html
#!pip install scikit-learn
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import sklearn
from sklearn import datasets
random.seed(1234)
print(sklearn.__version__)
1.4.0
Example: Real Estate Price Prediction with sklearn 🏡#
In this example we will use the sklearn library to predict the price of a house in Boston, from a 70’s dataset.
Here is some info about the dataset:

1. We load the dataset
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
2. We set our features (X) and our target (y).
In our case, the target will be the median value of the house (MEDV), and the features will be the rest of the columns.
X, y = data, target
Question: What type of objects are X and y? And their dimensions?
X.shape, y.shape
((506, 13), (506,))
3. Data exploration
Let’s compute the the correlations between the features and the target.
corr = np.corrcoef(X, y, rowvar=False)[:, -1]
corr
array([-0.38830461, 0.36044534, -0.48372516, 0.17526018, -0.42732077,
0.69535995, -0.37695457, 0.24992873, -0.38162623, -0.46853593,
-0.50778669, 0.33346082, -0.73766273, 1. ])
Question: What feature is the most correlated with the target?
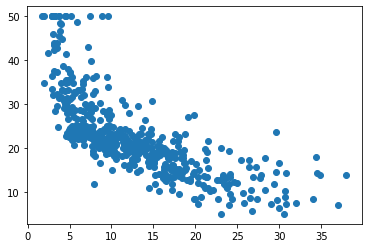
# LSTAT
idx = -1
Plot a scatter plot of the most correlated feature with the target.
x = X[:, idx] # we pick this feature for later
fig, ax = plt.subplots()
plt.scatter(x, y)
<matplotlib.collections.PathCollection at 0x16a03d580>
4. Fitting a model
Let’s start fitting a linear regression model. But first, we need to split our data into train and test sets.
In sklearn, we can do this with the function train_test_split. In this function, we can specify the size of the test set (20%, for example) and the random state (so everytime we get the same partition).
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1234, test_size=0.2)
Now we can fit the model with the train data. In sklearn, we can do this in the following steps:
Create an instance of the model
Fit the model to the train data using the
fitmethod
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(X_train, y_train)
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
We can inspect the coefficients of the model with the coef_ and intercept_ attributes.
beta = lm.coef_
beta0 = lm.intercept_
print(beta)
print(beta0)
[-1.02035256e-01 6.01151037e-02 3.47699609e-02 3.00350930e+00
-2.04147071e+01 2.89371393e+00 -5.32341284e-03 -1.76260440e+00
3.38923461e-01 -1.34787063e-02 -1.01921362e+00 1.03741454e-02
-5.25691400e-01]
45.737181228954654
5. Compute predictions over the test set and evaluate the model
y_pred = lm.predict(X_test)
Remember that when \(y\) is a continuous variable:
The linear regression model has the following parametric form:
where \(\hat{y} \in \mathbb{R}\) is the variable to predict and the data has \(p\) columns, \(x \in \mathbb{R}^p\).
Assuming a set of training data, \(\mathcal{D_{tr}} = \lbrace (x, y) \rbrace\), the parameters \(\beta, \beta_0\) can be adjusted by solving the following optimization problem (minimization):
On another evaluation set \(\mathcal{D_{te}}\), we can evaluate the quality of the predictions. The most common ones are
Mean squared error \(\text{MSE}(y, \hat{y}) = \frac{1}{n_\text{samples}} \sum_{i=0}^{n_\text{samples} - 1} (y_i - \hat{y}_i)^2\)
Mean absolute error \(\text{MAE}(y, \hat{y}) = \frac{1}{n_{\text{samples}}} \sum_{i=0}^{n_{\text{samples}}-1} \left| y_i - \hat{y}_i \right|\)
Coefficient of determination \(R^2(y, \hat{y}) = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2}\)
The \(R^2\) represents the proportion of variance explained. The best score is 1. A constant model that always predicts the mean of the population \(y\) would get 0, and worse models would have negative \(R^2\).
# compute the MAE
mae = np.mean(np.abs(y_test - y_pred))
mae
3.5789349138336166
Is this error good or bad? We can compare it with the mean of the target in the test set.
y_test.mean()
23.019607843137255
So it’s like 15% of relative error.
To compute the R^2 score, we can use the score method of the model:
r2 = lm.score(X_test, y_test)
r2
0.7665382927362874
Seems kinda good
Question : Which variable has the highest (positive) impact on the price of a house?
6. Using different models
Decision trees#
from sklearn.tree import DecisionTreeRegressor # always mind the Regressor or Classifier variant, depending on the task
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mae = np.mean(np.abs(y_test - y_pred))
mae
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/var/folders/l_/k13w4mhd5hv4bddxwqz8qdfw0000gn/T/ipykernel_1665/1515305590.py in <module>
1 from sklearn.tree import DecisionTreeRegressor # always mind the Regressor or Classifier variant, depending on the task
2 model = DecisionTreeRegressor()
----> 3 model.fit(X_train, y_train)
4 y_pred = model.predict(X_test)
5
NameError: name 'X_train' is not defined
from sklearn.tree import plot_tree
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
fig, ax = plt.subplots(figsize=(13, 13))
plot_tree(model, ax=ax, feature_names=feature_names, filled=True);
plt.savefig("tree.png", dpi=700)

An ensemble of decision trees, trained over subsets of the data, is called a random forest. Random forests are among the most popular machine learning methods thanks to their relatively good accuracy, robustness and ease of use.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mae = np.mean(np.abs(y_test - y_pred))
mae
1.9635980392156864
Recap scikit-learn#
Scikit-learn is a collection of classical machine learning models over numpy arrays.
Very easy to use: same functions for all models: fit and predict.
Classifier example: handwritten digit recognition 📝#
We will use the digits dataset from sklearn. This dataset contains 1797 images of digits (8x8 pixels), and the target is the digit itself (10 classes: 0 to 9).
Handwritten character recognition is a typical problem in computer vision, and one of the first successful applications of (deep) machine learning, in applications like:
Postal services
Banks, for check processing
from sklearn.datasets import load_digits
digits = load_digits()
X, y = digits.data, digits.target
X.shape
(1797, 64)
plt.hist(y, bins=10, rwidth=0.8);
print(digits.DESCR)
.. _digits_dataset:
Optical recognition of handwritten digits dataset
--------------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 1797
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
This is a copy of the test set of the UCI ML hand-written digits datasets
https://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
The data set contains images of hand-written digits: 10 classes where
each class refers to a digit.
Preprocessing programs made available by NIST were used to extract
normalized bitmaps of handwritten digits from a preprinted form. From a
total of 43 people, 30 contributed to the training set and different 13
to the test set. 32x32 bitmaps are divided into nonoverlapping blocks of
4x4 and the number of on pixels are counted in each block. This generates
an input matrix of 8x8 where each element is an integer in the range
0..16. This reduces dimensionality and gives invariance to small
distortions.
For info on NIST preprocessing routines, see M. D. Garris, J. L. Blue, G.
T. Candela, D. L. Dimmick, J. Geist, P. J. Grother, S. A. Janet, and C.
L. Wilson, NIST Form-Based Handprint Recognition System, NISTIR 5469,
1994.
|details-start|
**References**
|details-split|
- C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their
Applications to Handwritten Digit Recognition, MSc Thesis, Institute of
Graduate Studies in Science and Engineering, Bogazici University.
- E. Alpaydin, C. Kaynak (1998) Cascading Classifiers, Kybernetika.
- Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin.
Linear dimensionalityreduction using relevance weighted LDA. School of
Electrical and Electronic Engineering Nanyang Technological University.
2005.
- Claudio Gentile. A New Approximate Maximal Margin Classification
Algorithm. NIPS. 2000.
|details-end|
Let’s plot a few examples of the dataset:
_, axes = plt.subplots(nrows=1, ncols=10, figsize=(10, 3))
for ax, image, label in zip(axes, digits.images, digits.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r)
ax.set_title("Label: %i" % label)
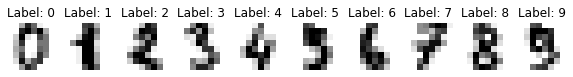
Using multiclass logistic regression#
For multiclass logistic regression - a generalization of the binary logistic regression to more than two classes, the model has the following parametric form:
where \(y\) can take possible values \(1, 2, \ldots, K\), so there are \(K\) sets of parameters \(\beta, \beta_0\) to be learned. Each set gives the (unnormalized probabilities) of the inputs being in one particular category.
Given a set of training data, \(\mathcal{D_{tr}} = \lbrace (x, y) \rbrace\), these parameters can be estimated by solving the following optimization problem (maximization):
or equivalently (minimization):
On another evaluation set \(\mathcal{D_{te}}\), we can evaluate the quality of the predictions. For multiclass problems, a common score is the accuracy:
Accuracy \(\text{ACC}(y, \hat{y}) = \frac{1}{n_{\text{samples}}} \sum_{i=0}^{n_{\text{samples}}-1} 1_{\lbrace \hat{y}_i = y_i \rbrace}\)
where \(1_{\lbrace \hat{y}_i = y_i \rbrace}\) is the indicator function which is equal to 1 if \(\hat{y}_i\) equals \(y_i\) and 0 otherwise.
Other common metrics typically used for multiclass classification include:
Macro-averaged precision, recall and F-score
Micro-averaged precision, recall and F-score
Weighted precision, recall and F-score
(we will further study them during the course)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=0.1)
from sklearn.linear_model import LogisticRegression
Exercise 1 Fit a logistic regression model to the digits dataset. Compute the accuracy on the test set.
model = LogisticRegression(max_iter=10000)
model.fit(X_train, y_train)
LogisticRegression(max_iter=10000)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression(max_iter=10000)
y_pred = model.predict(X_test)
np.mean(y_pred == y_test)
0.9611111111111111
from sklearn.metrics import accuracy_score
accuracy_score(y_pred, y_test)
0.9611111111111111
Exercise 2 Can you improve the accuracy by using a different model?
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test)
0.9666666666666667
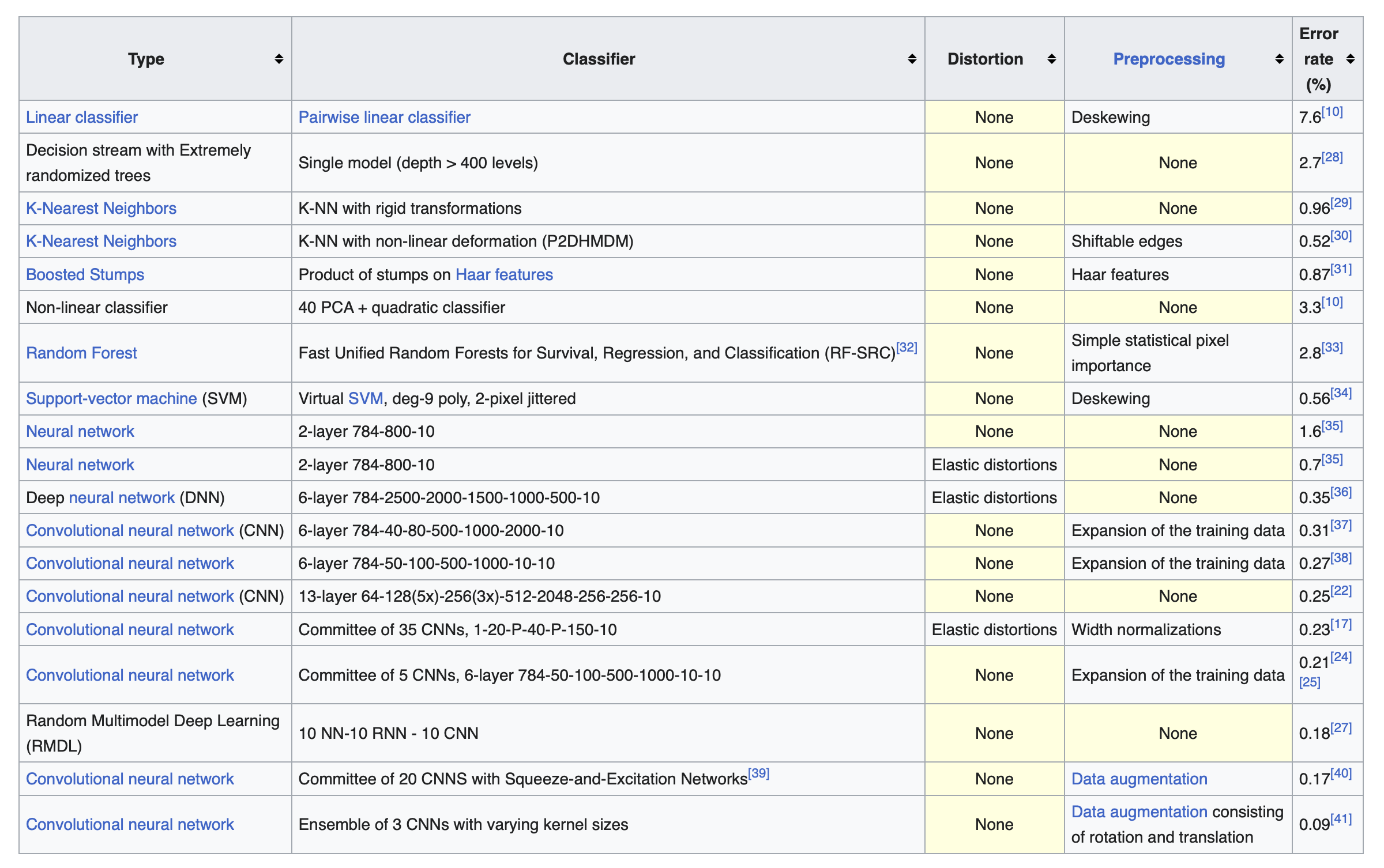
Recap: through the previous accuracies may seem high, they are not that good.
The following is a list of error rates (100 - accuracy %) obtained over a very similar dataset (MNIST) by different methods:
https://en.wikipedia.org/wiki/MNIST_database